[헬로티]
▷▶크웬튼 홀(Quenton Hall) 자일링스 산업·비전·헬스케어 부문 AI 시스템 설계자
신경망은 새로운 데이터를 통합하여 ‘학습’할 수 있는 인간의 두뇌를 모델링한 일련의 알고리즘으로 분류할 수 있다. 실제로 특수 목적에 맞게 ‘효율적인 컴퓨팅’을 제공하는 신경망 모델을 개발하면, 많은 이점을 얻을 수 있다. 그러나 이러한 모델의 효과를 높이기 위해서는 몇 가지 주요 요건들을 고려해야 한다.


추론 가속기(또는 일반적인 하드웨어 가속기)를 구현할 때 고려해야 할 중요한 사항 중 하나는 메모리 액세스 방법과 관련이 있다. 머신러닝 추론의 경우 가중치는 물론, 중간 활성화(Activation) 값까지 모두 저장할 수 있는 방법을 구체적으로 고려해야 한다. 지난 몇 년간 여러 기법들이 사용되었고, 다양한 성공률을 기록했다. 또한 관련 아키텍처의 선택도 중요한 영향을 미친다.
- 지연시간: L1, L2, L3 메모리에 대한 액세스는 비교적 짧은 대기시간에 이뤄진다. 다음 그래프 작업과 관련된 가중치와 활성화가 캐시되면, 합리적인 수준의 효율을 유지할 수 있다. 그러나 외부 DDR에서 가져와야 하는 경우, 파이프라인의 중단이 발생하고, 지연시간과 효율성에 영향을 미칠 수 있다.
- 전력소비: 외부 메모리와 액세스하는데 소모되는 에너지는 내부 메모리와 액세스하는 것보다 적어도 한 자릿수 이상 더 높다.
- 컴퓨팅 포화: 일반적으로 애플리케이션은 컴퓨팅이나 메모리에 종속되는 경우가 많다. 이는 주어진 추론 패러다임에서 달성할 수 있는 GOP/TOPS에 영향을 줄 수 있으며, 경우에 따라 이러한 영향이 매우 중요할 수 있다. 특정 네트워크를 구축할 때 실제 성능이 1 TOP일 경우, 10 TOPS의 피크 성능을 달성할 수 있는 추론 엔진의 가치는 떨어지게 된다.
- 한 단계 더 나아가 최신 자일링스 디바이스의 내부 SRAM(자일링스 SoC에 익숙한 사람들에게는 BRAM 또는 UltraRAM으로 알려짐)과 액세스하는데 소요되는 에너지는 피코줄 수준에 불과하며, 이는 외부 DRAM과 액세스하는데 소요되는 에너지보다 약 두 자릿수 정도 적은 규모이다.
한 가지 아키텍처 예제로, TPUv1을 고려할 수 있다. TPUv1은 중간 활성화 값을 저장할 수 있는 28MB 온칩 메모리와 65,536개의 INT8 MAC 유닛을 통합하고 있다. 가중치는 외부 DDR에서 가져온다. TPUv1의 이론적 피크 성능은 92 TOPS이다.
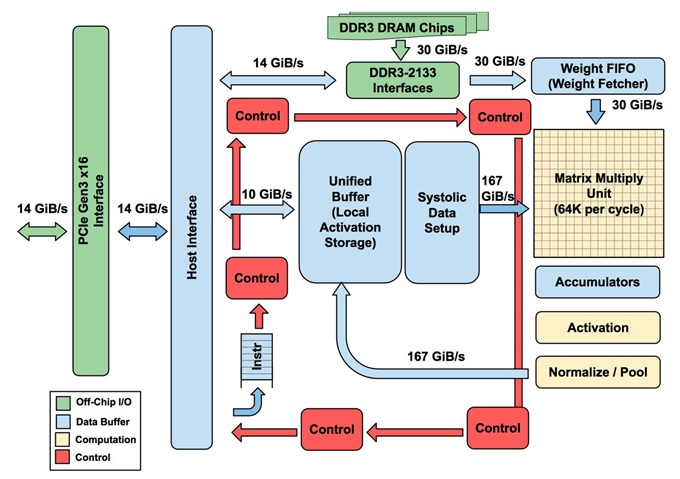
그림 1. TPUv1 아키텍처 (참조: 주피(Jouppi et al.) 2017)
TPU는 그래프 작업을 스케쥴링하기 위해 복잡한 컴파일러를 사용하는 매우 일반화된 텐서(Tensor) 가속기 중 한 예이다. TPU는 특정 작업부하에서 매우 뛰어난 효율의 처리량을 나타냈다(86 TOPS의 CNN0 참조). 그러나 CNN의 메모리 레퍼런스 기반 컴퓨팅 비율은 MLP나 LSTM보다 낮았으며, 이 특정 작업부하가 메모리에 종속되어 있음을 알 수 있다. 또한 CNN1은 새로운 가중치를 매트릭스 유닛에 로드해야 하는 경우 직접적인 파이프라인 중단을 초래해 성능을 약화(14.1 TOPS)시킨다.
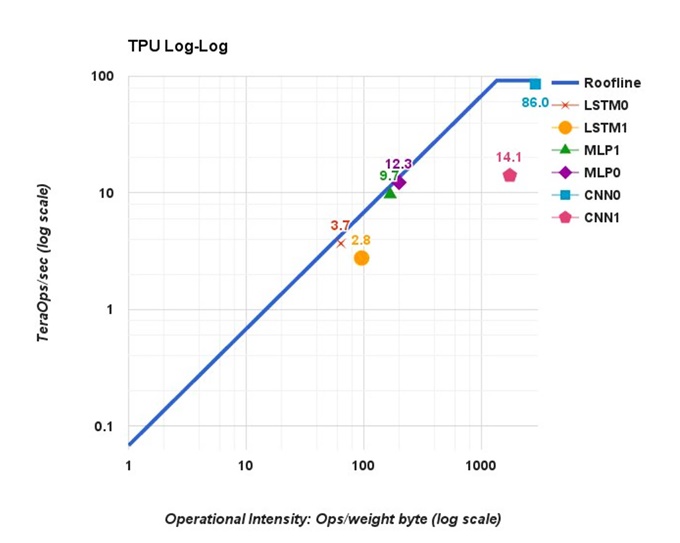
그림 2. 다양한 네트워크 토폴로지를 위한 TPUv1 성능 그래프
신경망 아키텍처는 성능에 상당한 영향을 미친다. 따라서 가속화해야 하는 특정 작업부하에 대한 높은 수준의 효율을 달성할 수 없다면 추론 솔루션을 선택하는데 있어 피크 성능 값은 큰 의미가 없다. 오늘날 많은 SoC 및 ASSP, GPU 공급업체들은 LeNet, AlexNet, VGG, GoogLeNet, ResNet과 같은 전통적인 이미지 분류 모델에 대한 성능 벤치마크를 계속해서 강조하고 있다. 그러나 이미지 분류 작업이 적용되는 실제 사례는 그 수가 제한적이며, 이러한 모델은 객체 감지 및 분할과 같은 보다 복잡한 작업에서 백엔드 기능 추출기로만 적용되는 경우가 많다.
보다 현실적인 실제 구축 가능한 모델 사례는 객체 감지 및 분할이다. 10 TOPS 성능을 제공한다는 많은 반도체 디바이스들이 시장에 출시되고 있지만, YOLOv3 및 SSD와 같은 네트워크에 대한 공식적인 IPS 벤치마크를 찾는데 오랜 시간과 노력이 필요하다는 점은 어떻게 설명할 수 있을까? 물론, 클라우드 스토리지에서 고양이 사진을 간단히 그랩(Grep)해야 한다면, 이러한 이슈는 큰 문제가 되지 않을 것이다[그림 3].

그림 3. 퀸튼 홀이 입양한 고양이, ‘텀블위드(TumbleWeed)’
많은 개발자들이 AI 지원 제품을 설계할 때 대부분 첫 번째 시도에서 성능 요건을 충족하지 못하고, 설계 중반에 다른 아키텍처로 전환한다는 사실은 놀라운 일이다. 만약 SOM 베이스 보드와 하드웨어 및 소프트웨어를 모두 재설계해야 한다면 이는 특히 어려운 문제가 된다. 자일링스 SoC를 선택하는 주요 동기는 경쟁 솔루션과 달리 자일링스의 추론 솔루션은 동일한 프로세서와 동일한 추론 가속기 아키텍처를 유지하면서도 한 자릿수 이상의 성능으로 곧바로 확장이 가능하기 때문이다.
2017년에 구글의 연구팀은 모바일 애플리케이션을 대상으로 한 새로운 차원의 모델을 발표했다. (하워드(Howard et al.), “MobileNets: 모바일 비전 애플리케이션을 위한 효율적인 CNN(Convolutional Neural Network)”) MobileNet의 장점은 높은 수준의 정확도를 유지하면서도 소요되는 컴퓨팅을 크게 줄였다는 점이다. MobileNet 네트워크에 적용된 중요한 혁신 중 하나는 분리 가능한 DWC(Depth-Wise Convolution)이다. 전통적인 콘볼루션에서는 모든 입력 채널이 모든 출력 채널에 영향을 미친다. 100개의 입력 채널과 100개의 출력 채널이 있으면, 100x100의 가상 경로가 생긴다. 그러나 DWC의 경우 콘볼루션 레이어를 100개의 그룹으로 분할하여 단 100개의 경로만 갖게 된다. 각 입력 채널은 단 하나의 출력 채널과 연결되기 때문에 컴퓨팅을 상당히 줄일 수 있다.
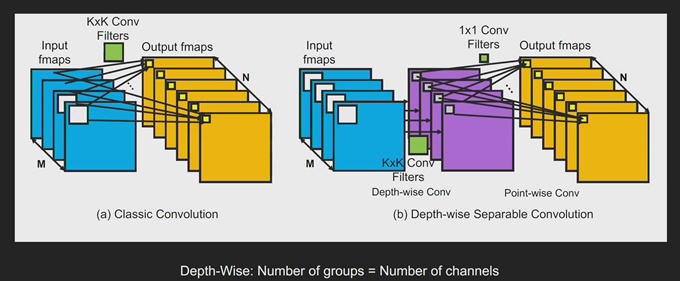
그림 4. 전통적인 콘볼루션과 DWC(Depth-Wise Convolution) 연결 비교
MobileNet의 결과 중 하나는 메모리 대비 컴퓨팅 비율이 감소한다는 것인데, 이는 높은 처리량을 달성하는데 메모리 대역폭과 지연시간이 보다 중요한 역할을 수행한다는 것을 의미한다.
하지만 컴퓨팅이 효율적인 네트워크가 반드시 하드웨어 친화적인 것은 아니다. 이상적으로는 지연시간이 FLOP 감소에 비례하여 줄어들어야 한다. 하지만 사람들이 말하는 것처럼, 공짜는 없다. 예를 들어, 아래의 비교 그래프를 보면, MobileNetv2의 컴퓨팅 작업부하가 ResNet50의 작업부하에 비해 10분의1 정도 작지만, 지연시간은 동일한 궤적을 따르지 않는다.
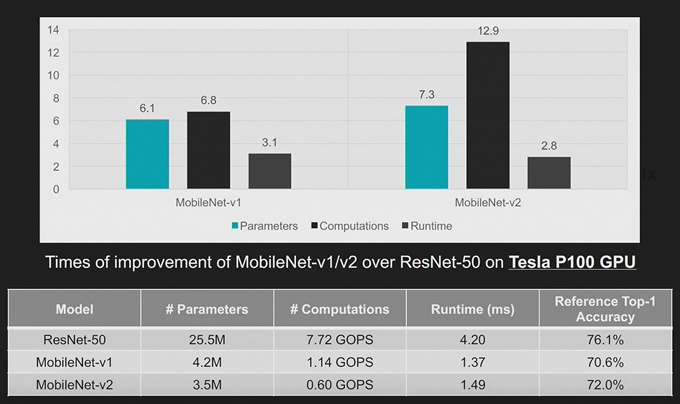
그림 5. MobileNet과 ResNet50의 운영 및 지연시간 비교
[그림 5]의 분석에 따르면, FLOP의 감소에 비례하여 지연시간이 12배까지 줄어들지 않는다는 것을 알 수 있다. 그렇다면 이 문제를 어떻게 해결할 수 있을까? 컴퓨팅 전반의 오프칩 통신 비율을 비교하면, MobileNet의 프로파일이 VGG와 매우 다르다는 것을 알 수 있다. DWC 레이어의 경우, 비율이 0.11임을 확인할 수 있다. 가속기는 메모리에 종속되어 있고, 프로세싱 요소(PE: Processing Element) 어레이의 많은 부분들이 데이터센터의 ‘다크(Dark)’ 서버처럼 상주하면서 전력 및 다이 영역 만을 차지하고, 유용한 작업은 수행하지 않기 때문에 효율이 떨어지게 되는 것이다.
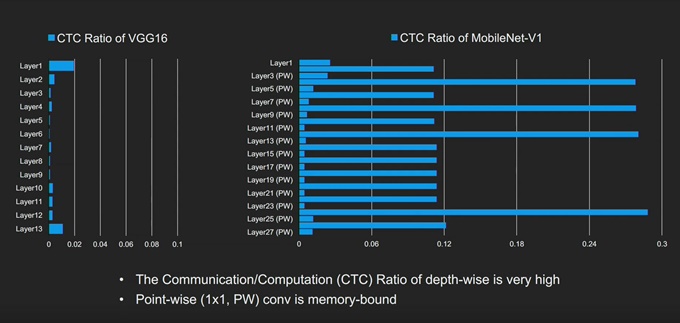
그림 6. VGG16 및 MobileNetv1의 CTC 비율
자일링스가 DPUv1을 출시했을 때 기존의 콘볼루션을 가속화(다른 운영보다)하도록 설계했다. 기존의 콘볼루션은 입력에 대한 적절한 채널(Channel-Wise) 감소가 필요하다. 이러한 감소를 통해 가중치/활성화 스토리지 보다 컴퓨팅 비율을 증가시키기 때문에 하드웨어 추론에 더욱 적합하다. 컴퓨팅 대비 메모리에 소요되는 에너지를 고려하면, 이는 매우 좋은 방법이다. ResNet 기반 네트워크가 고성능 애플리케이션에 널리 구축되고 있는 것도 이러한 이유 때문이며, ResNet을 사용하면 메모리 대비 컴퓨팅 비율이 다른 기존의 백본들 보다 높다.
DWC는 이러한 채널 감소에 따른 결과를 얻을 수 없다. 메모리 성능이 훨씬 중요하기 때문이다. 추론의 경우, 일반적으로 DWC를 PWC(Point-Wise Convolution)와 융합하고, 온칩 메모리에 DWC 활성화 값을 저장한 다음, 1x1 PWC를 즉시 시작한다. 원래의 DPU에서는 DWC를 위한 특화된 하드웨어 지원이 없었기 때문에 이상적인 효율을 달성할 수 없었다.

그림 7. MobileNet과 ResNet50의 운영 및 지연시간 비교 – DPUv1(기본적으로 DWC 지원이 안됨)
하드웨어에서 DWC 성능을 가속하기 위해 자일링스는 DPU의 프로세싱 요소에 대한 기능을 수정하고, DWC 오퍼레이터를 PWC와 융합했다. 첫 번째 레이어에서 하나의 출력 픽셀이 처리된 다음, 활성화 값을 DRAM에 작성하지 않고 1x1 콘볼루션(DPU의 온칩 BRAM 메모리를 통해)으로 즉시 파이프라인 된다. 이러한 특화된 기법을 이용해 DPU에 구축되는 MobileNet의 효율을 크게 향상시킬 수 있다.
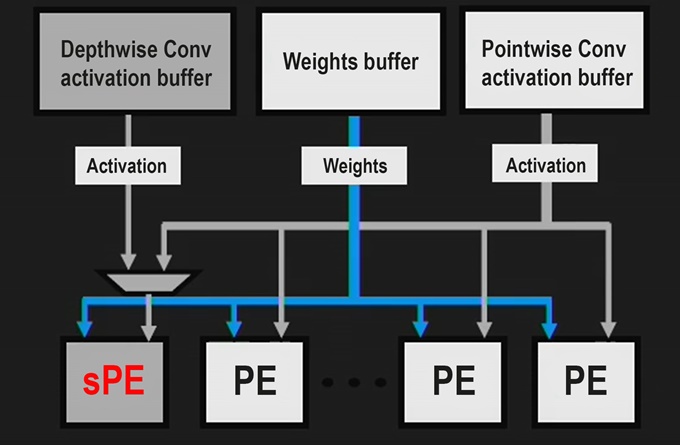
그림 8. DPUv2, 특화된 DWC 프로세싱 요소
우리는 수정된 DPUv2 아키텍처를 통해 MNv1 추론 효율을 획기적으로 개선할 수 있었다. 또한 온칩 메모리 용량을 증가시키면, ResNet50 결과와 동등하게 효율을 더욱 높일 수 있다. 이러한 모든 것은 동일한 CPU와 하드웨어 아키텍처를 이용해 달성되었다.
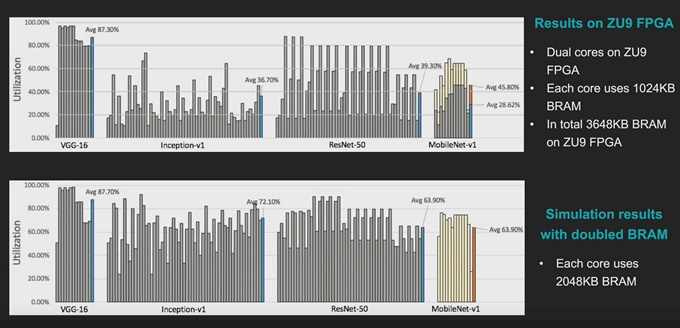
그림 9. MobileNet 및 ResNet50의 구축 지연시간, DPUv1 대 DPUv2(DWC 지원)
보통은 추론 하드웨어와 신경망 모델을 서로 분리하여 최적화한다. 네트워크는 일반적으로 GPU를 사용해 트레이닝되고, 매우 다른 아키텍처를 가진 엣지의 SoC나 GPU에 구축된다. 실제로 성능을 최적화하기 위해서는 하드웨어에 적합하지 않은 모델을 효율적으로 구축할 수 있도록 하드웨어 조정이 필요하다. 이러한 상황에서 적응형 하드웨어인 자일링스 디바이스의 주요 이점은 소프트웨어 및 하드웨어가 배치된 이후에도 계속해서 이를 발전시킬 수 있는 독보적인 기회를 제공한다는 것이다.
한 단계 더 나아가 ‘복권의 가설(Lottery Ticket Hypothesis)’이라는 주제의 획기적인 논문의 내용을 살펴보도록 하자(프랭클(Frankle) 및 카빈(Carbin), 2019 https://arxiv.org/pdf/1803.03635.pdf). 이 논문(ICLR2019에서 두 명의 최고상 수상자 중 한 사람)에서 저자는 “밀도가 높고, 무작위로 초기화된 피드-포워드(Feed-Forward) 네트워크는 서브네트워크(우승 티켓)를 포함하고 있으며, 이는 격리된 트레이닝의 경우 유사한 반복 횟수(트레이닝)에서 원래의 네트워크와 견주되는 테스트 정확도를 달성한다”는 가설을 제시한다. 이는 네트워크 프루닝(Pruning)의 미래는 밝고, AutoML과 같은 기법은 조만간 네트워크 디스커버리 및 최적화 프로세스를 위한 ‘우승 티켓’을 우리에게 보여줄 것임을 시사하고 있다.

그림 10. 퀸튼 홀이 제시한 ‘우승 티켓(Winning Ticket)’ 가설
또한 전통적인 백본에 대한 채널 프루닝은 현재 엣지에서 효율적이고 높은 정확도를 구현할 수 있는 최상의 솔루션으로 여전히 유지되고 있다. 이러한 백본은 구축에 있어 비효율적일 수 있지만, 백본의 반자동 채널 프루닝은 매우 효율적인 결과를 제공할 수 있다(자일링스 VGG-SSD 예제 참조). 따라서 미래지향적인 차세대 설계를 위한 추론 아키텍처를 선택함으로써 현재에도 ‘우승 티켓’을 간단히 찾을 수 있다는 이 가설을 분명히 현실화할 수 있으며, 고객의 제품 수명을 보장하면서 미래의 네트워크 아키텍처와 최적화 기술을 활용할 수 있다.
‘복권의 가설(Lottery Ticket Hypothesis)’에서 파생된 미래에 대한 연구는 더욱 뛰어난 효율성을 달성할 수 있는 차세대 프루닝 기법으로 나아갈 수 있는 가능성을 제시했다. 또한 다차원적으로 확장이 가능한 적응형 하드웨어 만이 이러한 우승 티켓을 찾을 수 있는 수단을 제공할 것이라는 점은 더욱 분명해졌다. 지금 ZCU104를 채택하고, 바이티스-AI(Vitis-AI)를 다운로드하여 미래의 AI를 위한 여정을 시작해 보자.